


NOTA DE TAPA
Certificación ISCC para producción de diesel renovable: un hito en la industria de refinación nacional
La experiencia de certificación ISCC-EU en producción de diésel renovable coprocesado aporta criterios técnicos y de gestión para implementar esquemas de operación mixta en refinerías, asegurando trazabilidad de la cadena productiva y reconocimiento de la reducción de emisiones.
Por María Belén Brest, Juan Martín Goldsack, Martín Gravagno y Cecilia Trapani (Raízen Argentina)
Este trabajo fue seleccionado en el 7.º Congreso Latinoamericano y del Caribe de Refinación.
- Introducción
Con el objetivo de avanzar en la transición energética, la refinería Raízen realizó en los años 2022 y 2023 pruebas de incorporación de materia prima renovable para Coprocesar junto con la alimentación fósil en la unidad hidrotratadora de diesel, logrando para 2024 un Coprocesamiento continuo en la unidad.
Una vez consolidado el nuevo modo de operación de Coprocesamiento, surgió el siguiente desafío del proyecto, poder comercializar estos productos dentro de un marco que asegure y demuestre la sostenibilidad en su producción. Surge entonces el objetivo de certificar dicha operación bajo el estándar ISCC (International Sustainability and Carbon Certification), reconocido y obligatorio en la Unión Europea para la comercialización de biocombustibles, pero totalmente nuevo para nuestro país en lo referente a unidades de coproceso.
En el siguiente proyecto se presentan los principales desafíos afrontados en el proceso de certificación
- Desarrollo
- El comienzo del Coproceso en la Refinería
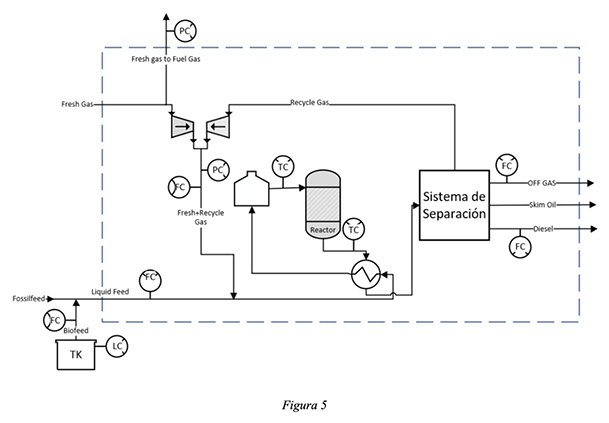
La unidad definida para coprocesar en la refinería fue la hidrotratadora de Diesel. Esta unidad se encuentra operando desde 1997. Se diseñó originalmente para eliminar el azufre de una mezcla de corrientes de diesel livianos, pesados y craqueados de origen fósil, bajo una alta presión parcial de hidrógeno. El proceso consta de una sección de purificación de gas fresco, una sección de reacción y una sección de procesamiento final.
En el año 2022, se decidió comenzar con el proyecto para incorporar materia prima de origen renovable, biofeeds, lo que implicó realizar adaptaciones en la refinería, tanto para el ingreso y almacenamiento de la materia prima, como para el procesamiento de la misma en la hidrotratadora.
En conjunto entre los equipos de Refinería y Suministros&Trading, se realizó un estudio de las posibles materias primas existentes en el mercado, se definió la calidad del producto que requeríamos para su procesamiento, y se comenzó con la búsqueda de proveedores. La materia prima elegida fue el aceite de soja pretratado.
Para el almacenamiento se definió utilizar un tanque existente. En las inmediaciones del mismo se construyó un descargadero de camiones dedicado para biofeeds. Para la alimentación a la hidrotratadora se utilizó una línea dedicada.
Del lado de Ingeniería de Procesos, se realizaron pruebas piloto donde se analizó el impacto del coproceso en la unidad, se realizó una evaluación de riesgos, se definieron las medidas de mitigación necesarias y finalmente se validó un modo operativo de Coprocesamiento en la unidad.
Por último, con el coproceso se sumó un nuevo producto final, el diesel renovable, el cual se produce y almacena en conjunto con el diesel fósil tradicional.
- La comercialización del Diesel Renovable
Lograr un coproceso continuo en la refinería conllevo a una producción sostenida y con escala comercial de diesel renovable. Sin embargo, la comercialización de este nuevo producto aun siendo posible, no se encuentra regulada en el mercado de combustibles local.
A nivel compañía era vital poder comercializar este producto dentro de un marco que asegure y demuestre la sostenibilidad en su producción, lo que nos llevó a dar un paso más y buscar una certificación internacional de sustentabilidad para este nuevo producto.
ISCC-EU fue el sistema de certificación elegido ya que garantiza que las materias primas renovables utilizadas para la producción de combustibles renovables sean trazables, sostenibles y que contribuyan efectivamente a la reducción de emisiones, y además permite cuantificar dicha reducción asegurando así el valor agregado del producto final.
ISCC es reconocido y obligatorio en la Unión Europea para la comercialización de biocombustibles, pero totalmente nuevo a nivel coprocesamiento en Refinerías en nuestro país.
- El camino hacia la certificación
En el contexto de una refinería en nuestro país, la adopción de procesos de gestión alineados con los estándares exigidos por la certificación ISCC representó una oportunidad estratégica para comenzar a integrarnos a cadenas de valor globales orientadas a la sostenibilidad.
Implementar estos estándares no solo nos permite cumplir con los requisitos regulatorios internacionales, sino también posicionar a la refinería como un actor comprometido con la transición energética.
La certificación ISCC exige una gestión rigurosa de la trazabilidad, control de documentación, cadena de custodia y reducción de emisiones, lo cual impulsa la optimización operativa, fortalece la transparencia de nuestro proceso productivo y abre las puertas a mercados/clientes que valoran productos de origen renovable certificado.
- Desarrollo de trazabilidad y cadena de custodia
La implementación de sistemas de trazabilidad y cadena de custodia es fundamental para obtener la certificación ISCC EU, ya que permite demostrar de forma transparente la reducción de emisiones de gases de efecto invernadero (GEI) asociada al coprocesamiento.
La trazabilidad asegura que se pueda rastrear el flujo de la materia prima desde su origen hasta el producto final, asignando a cada lote características específicas como el tipo de materia prima, procesamiento de la misma y emisiones asociadas. Por su parte, la cadena de custodia define cómo se gestionan las mezclas de materias primas renovables y fósiles dentro del proceso.
- Trazabilidad Raízen
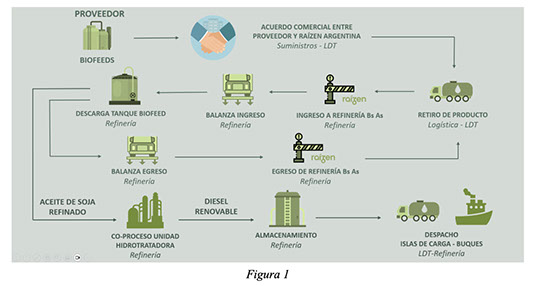
Para asegurar la trazabilidad en nuestro proceso productivo, necesitamos que nuestros proveedores de materia prima también se encuentren certificados por ISCC, lo que implicó la necesidad de realizar acuerdos comerciales con proveedores de materia prima que se encuentren certificados y que además cumplan con nuestros estándares de calidad de producto para su Coprocesamiento.
La evidencia de las características de sostenibilidad se transmite a lo largo de la cadena mediante Declaraciones de Sostenibilidad – DS. Estas declaraciones incluyen la cantidad de material suministrado, las emisiones asociadas y es el certificado que confirma que el proveedor está certificado bajo ISCC. Actualmente recibimos la materia prima renovable en lotes, donde cada uno de estos lotes trae asociado su DS.
Para la gestión integral del transporte y la descarga en refinería de la materia prima, se desarrolló un portal web dedicado que permite la integración de todos los actores involucrados en la operación logística. Esta herramienta digital facilita la coordinación, el seguimiento en tiempo real y la trazabilidad documental de cada entrega, asegurando eficiencia operativa y cumplimiento con los requisitos del sistema de certificación ISCC.
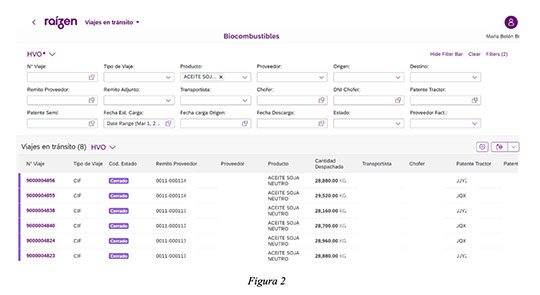
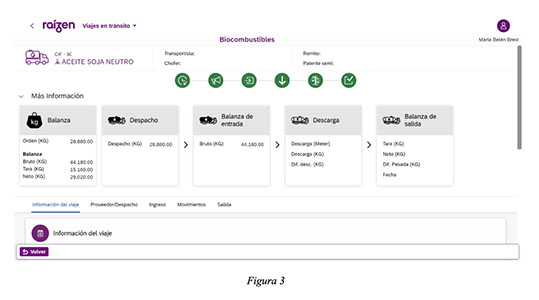
El transporte de materia prima desde el proveedor hasta la refinería es mediante camiones dedicados. Para ISCC, el transporte no requiere certificación, pero si es necesario contar con toda la información relevante de cada transporte para el cálculo de emisiones asociadas: distancias recorridas, volumen por camión y datos físicos de la materia prima.
Una vez que el camión se presenta en la refinería, se inicia el proceso de recepción mediante su pesaje en una balanza calibrada, lo que permite registrar el peso bruto de ingreso. Posteriormente, el camión accede a las instalaciones y descarga el contenido en el tanque de materia prima. Finalizada la descarga, el camión vuelve a pasar por la misma balanza para registrar el peso de salida. La diferencia entre ambos registros constituye el volumen neto descargado, que se utiliza como dato calibrado y trazable del ingreso de materia prima renovable a la refinería.
Luego la materia prima es coprocesada en la unidad de hidrotratamiento junto con la alimentación fósil. La producción resultante —una mezcla de diésel fósil y renovable— se almacena en tanques certificados, cumpliendo con los requisitos de trazabilidad y segregación. Aunque el producto se despacha en forma equivalente al diésel convencional desde el punto de vista físico y comercial, a nivel ISCC se genera un valor agregado mediante la emisión de créditos de diésel renovable sobre la fracción correspondiente dentro del diesel coprocesado.
Estos créditos se formalizan a través de un certificado de sostenibilidad (Proof of Sustainability, PoS), que se emite una vez que el producto ha sido vendido bajo los términos del sistema ISCC. El PoS contiene toda la información necesaria para demostrar el cumplimiento de los criterios de sostenibilidad y reducción de emisiones, incluyendo el tipo y origen de la materia prima, el ahorro de emisiones de GEI, y el volumen certificado como renovable. Este mecanismo permite que el valor ambiental del producto se reconozca y se transfiera a lo largo de la cadena de suministro, incluso cuando el producto físico renovable no se comercializa de forma segregada del fósil.
- Cadena de custodia Raízen
En Raízen optamos por utilizar como cadena de custodia el método de balance de masa, ya que permite la mezcla física de materiales fósiles y renovables, siempre que se presente un control documental que asegure que la cantidad de diesel renovable producido y certificado no exceda la correspondiente al procesamiento de la cantidad de materia prima sostenible introducida en el procesamiento.
El mismo se lleva en forma independiente, por coproceso y por tipo de material, sostenible y fósil. Contiene la siguiente información:
- Inventario inicial y final de material fósil y renovable
- Ingreso de material renovable
- Reporte de producción: Créditos producidos de diesel renovable. Factor de conversión utilizado (Bioyield).
- Egreso de materiales con PoS de diesel renovable.
- Créditos de un periodo a otro
- El cálculo de ahorro de GEI – donde la sustentabilidad se materializa
El cálculo del ahorro de emisiones de gases de efecto invernadero (GEI) es el momento en que el valor ambiental del coprocesamiento se transforma en evidencia concreta. Una vez producido el diésel renovable, este cálculo permite cuantificar con precisión el impacto positivo del proceso, demostrando cuánto se ha reducido la huella de carbono en comparación con un combustible 100% fósil, a lo largo de todo el ciclo de vida del producto. No se trata solo de un requisito técnico, es la validación que respalda la sostenibilidad del producto final. Este dato, verificado y documentado bajo los estándares ISCC EU, es clave para posteriormente emitir el certificado de sostenibilidad (PoS). En resumen, el ahorro de GEI es lo que convierte al diésel renovable en una herramienta real de descarbonización.
- El punto crítico: el factor de conversión de biofeed a diesel renovable
El punto crítico para la certificación fue determinar cuánto biofeed efectivamente se estaba convirtiendo en diesel renovable.
El hidrotratamiento de aceite ocurre en etapas, donde cada una requiere distintas cantidades de H2. La primera etapa es la hidrogenación/saturación de los enlaces múltiples de las cadenas de ácidos grasos del triglicérido. El siguiente paso luego de la saturación del triglicérido consiste en el hidrocraqueo del mismo en una molécula de propano y tres ácidos grasos libres. Finalmente, para completar la conversión del ácido graso a hidrocarburo, la desoxigenación puede ocurrir de tres maneras distintas en función de los productos obtenidos:
Hidrodesoxigenación (HDO), Descarbonilación (DCN) o Descarboxylación (DCO):
Los subproductos del hidrotratamiento son: CH4, C3H8, CO, CO2 y H20; donde el % de cada subproducto va a depender de la reacción de desoxigenación que predomine
En el siguiente esquema se presentan las distintas posibilidades:
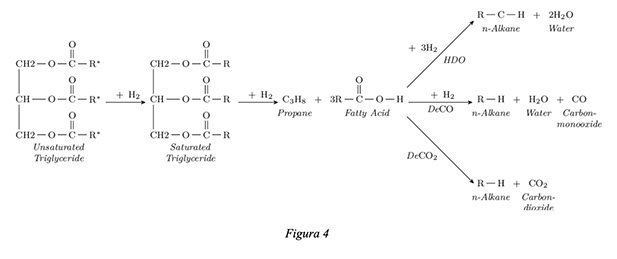
Para cualquiera de las posibles reacciones del biofeed, la estructura molecular final del diesel renovable es análoga a las moléculas de diesel de origen fósil, por lo que no es posible determinar de forma sencilla que moléculas representan diesel renovable. Es por este motivo que el desarrollo de un método para determinar el factor de conversión de nuestra materia prima renovable en diesel, aceite de soja pretratado, fue vital para nuestro proceso de certificación.
Previo al desarrollo del método, se realizó un cálculo de rendimiento teórico como información de diseño, utilizando el perfil de ácidos grasos de nuestra materia prima, y considerando un 100% de reacción de hidrodesoxigenación (HDO); obteniendo la máxima conversión teórica posible para el biofeed analizado.
El método que optamos desarrollar fue el método de rendimiento A descripto en ISCC 203-01 – Guidance for the certification of Co-Processing. Este método establece la comparación de escenarios con alimentación 100% fósil y escenarios con Coproceso, y se analizan los resultados para poder determinar el rendimiento de la materia prima de origen renovable. Este método se utiliza como método principal de cálculo.
Posteriormente, se realizó un test run en la unidad en dos etapas, una con alimentación 100% fósil y la segunda agregando alimentación renovable, y comparando ambos casos se pudo determinar un factor de rendimiento analítico.
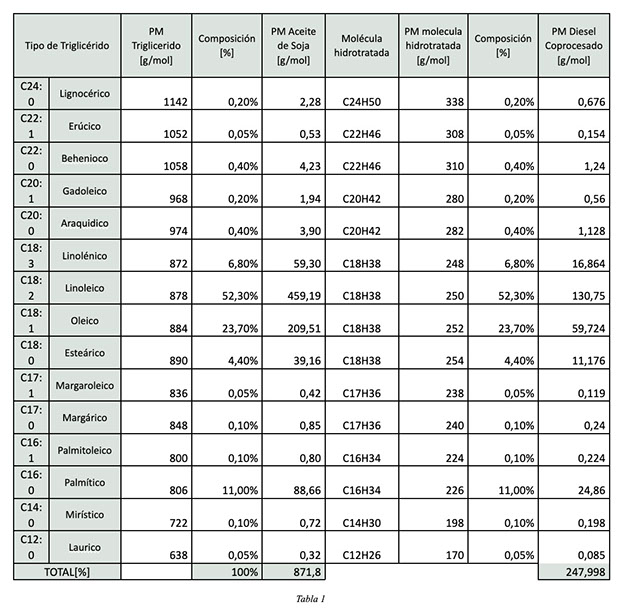
Se calcularon los pesos moleculares de cada triglicérido y se los multiplico por el % de composición en el aceite para determinar un peso molecular promedio de la materia prima. Lo mismo para el peso molecular Diesel Coprocesado
Se consideró un hidrotratamiento vía hidrodesoxigenación (HDO), donde:
Triglicérido (esteárico) + 12 H₂ → C₃H₈ + 3 n-C18 + 6 H₂O
Y el equivalente para todos los tipos de triglicéridos. De todos los tipos obtenemos 3 moléculas parafínicas (de cadenas de entre 12 a 24 carbonos, dependiendo del tipo)
Para definir el rendimiento [X], se lo calculó como la relación entre 3 moléculas de Diesel Coprocesado y la molécula de triglicérido, obteniendo un valor teórico de 85,34%. Luego, el restante 14,66% corresponde a la formación de subproductos
Los datos de las variables de proceso indicadas arriba se extrajeron del sistema PI, el cual funciona como base de almacenamiento de la información del sistema de control distribuído DCS que contiene la información en tiempo real de las variables de proceso de la unidad.
- Consideraciones generales:
- El bio-rendimiento calculado es basado en la alimentación total a la planta
- La unidad se encontraba operando en modo baja severidad (contenido de azufre en producción de 150ppm)
- Se mantuvieron constantes condiciones operativas de presión y temperatura
- Se mantuvieron constante las calidades de las alimentaciones fósiles a la unidad
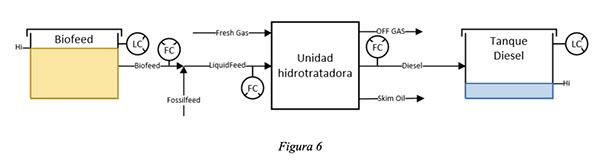
Se presentan además estas variables en un esquema de la hidrotratadora de Diesel:
Etapa 1: Carga 100% fósil
El test run comenzó estableciendo una carga 100% fósil
Se mantuvo la unidad operando estable en estas condiciones durante 8hs.
Se tomaron muestras para caracterizar analíticamente esta etapa. Se tomaron muestras de: alimentación combinada, producción Diesel, Gas Fresco y OFF Gas
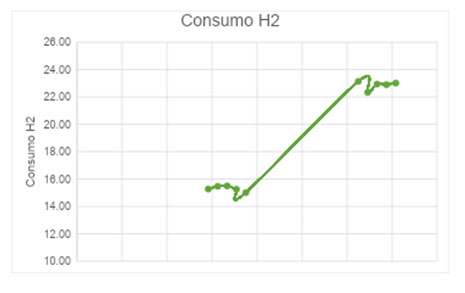
Con esta etapa obtuvimos dos datos clave: el consumo de hidrógeno de la carga fósil y el rendimiento de la alimentación fósil.
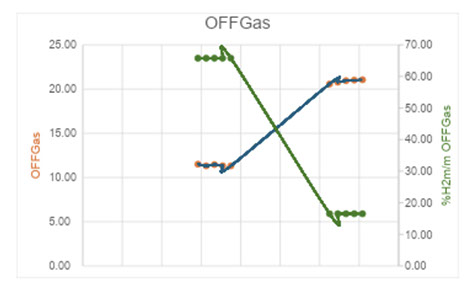
El consumo neto de hidrógeno en las reacciones de hidrodesulfurización se calculó como la entrada de gas fresco a la unidad; restando el OffGas remanente que se rutea a la unidad de tratamiento de gas; estos caudales normalizados por el % en peso de hidrógeno correspondiente, obtenidos de la cromatografía gaseosa analizada.

Etapa 2: Carga fósil + Bio
Para la segunda etapa del Test run se añadió carga Bio de forma escalonada, hasta llegar a un 6% de la alimentación; reduciendo la carga fósil para mantener la carga total en la unidad
Se mantuvo la planta operando estable en estas condiciones durante 6hs.
Se realizó una nueva ronda de muestreo para caracterizar analíticamente la etapa. Se tomaron nuevamente muestras de: Alimentación combinada, Producción Diesel, Gas Fresco y OFF Gas
Con esta segunda se pudo determinar el rendimiento de la carga fósil+bio.
Conclusiones método del rendimiento
Como highlights de este cálculo analítico, podemos destacar
- El resultado obtenido es coherente con los valores esperados, menor al máximo rendimiento teórico calculado
- Mayor caudal de ingreso de hidrógeno a la sección de reacción, indicador del mayor consumo de hidrógeno en el reactor para tratar el biofeed
- Mayor caudal corriente de OFFGas indicando por un lado una mayor producción de subproductos de reacción, pero con una disminución de contenido de hidrógeno (determinado a partir de las cromatografías gasesosas analizadas)
- Una pequeña disminución del caudal de producción de diesel
- Calibración con C14
Para validar la conversión de biofeed, se empleó el método directo por determinación de carbono 14 a un batch de coproceso de aceite de Soja pretratado
- Consideraciones generales:
- Se varió la proporción de Biofeed entre 2% y 6% teniendo como prioridad la estabilidad de la unidad
- Se mantuvieron constantes condiciones operativas de presión y temperatura
- La unidad se encontraba operando en modo baja severidad
- Se corrió la producción a un mismo tanque de diesel durante el tiempo que duró la corrida batch
- No se cambiaron calidades de alimentaciones fósiles a la unidad durante la corrida y se mantuvo la carga total a la unidad
Etapa 1: Situación inicial, previo al coproceso Batch
- Se tomó muestra del tanque de Biofeed, y se midió su altura inicial
- El tanque de diesel al cual se iba a correr la producción tenía un fondo no bombeable, se midió su altura inicial y se tomó una muestra para analizar C14, se estimaba que podía tener algún remanente de contenido biogénico ya que se había utilizado previamente para batchs de CoProceso
Etapa 2: Situación final, luego de la corrida del Batch
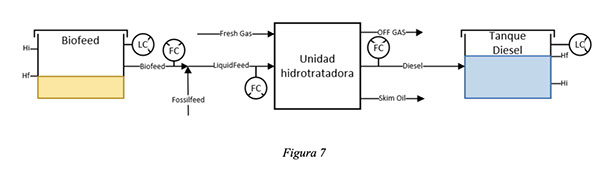
Luego de finalizar la corrida Batch:
- Se midió altura final del tanque de biofeeds, para poder con los datos físicos del tanque poder medir el volumen total alimentado, coprocesado y almacenado en el tanque de diesel
- Se recirculó el tanque de diesel durante 4hs para asegurar que el producto sea homogéneo
- Se midió altura final del tanque de diesel, para determinar el diesel total Batch producido y volumen final del tanque
- Se tomó muestra del tanque de diesel para analizar contenido de C14
- Comparación de resultados
Por metodología ISCC, la discrepancia entre métodos para validar el bio-rendimiento se calcula comparando los resultados obtenidos por el método principal de cálculo con los resultados del análisis de carbono 14, que actúa como referencia. Esta comparación se expresa como una diferencia porcentual entre ambos valores
En la siguiente tabla se estima el porcentaje de diesel de origen biogénico según los rendimientos calculados por los dos métodos explicados anteriormente.
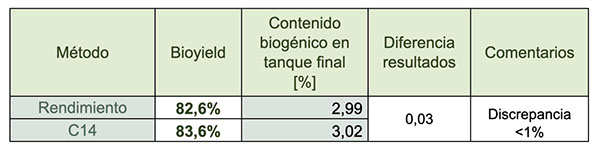
Como conclusión de estos análisis, pudimos validar un factor de bio-rendimiento de 82,6% para un Coproceso entre 2% y 6% de biofeed en la alimentación combinada.
- Índice
- RBA: Refinería Buenos Aires
- Biofeed: Materia prima de origen renovable
- ISCC: International Sustainability and Carbon Certification
- Diesel renovable: Diesel obtenido a partir del procesamiento de aceite vegetal
- HVO: Hydrotrated Vegetable Oil. Equivalente a Diesel renovable, nombre utilizado principalmente en Europa
- DS: Declaración de Sustentabilidad
- PoS: Proof of Sustainability
- LDT: Negocio de Logística, Distribución y Trading
- GEI: Gases de efecto invernadero
- AMS: Accelerator Mass Spectrometry
- Bibliografía
- ISCC 203-01 – Guidance for the certification of Co-Processing




> SUMARIO DE NOTAS
AOG Expo 2025: Innovación, negocios e integración regional en una edición histórica
Jóvenes Oil & Gas: Nuevas generaciones para una industria en transformación
Financiar el futuro energético: El desafío detrás del desarrollo de Vaca Muerta
Encuentros con los CEOs:
Visión estratégica para el futuro energético
> Ver todas las notas


Instituto Argentino del Petróleo y del Gas
Maipú 639 (C1006ACG) - Tel: (54 11) 5277 IAPG (4274)
Buenos Aires - Argentina
> SECCIONES
> NUESTRAS REDES
Copyright © 2025, Instituto Argentino del Petróleo y del Gas,todos los derechos reservados