


NOTA DE TAPA
IMPLEMENTACIÓN DE TECNOLOGÍA DE GEMELO DIGITAL COMO SISTEMA DE MANEJO DE LA ENERGÍA EN REFINERÍA CAMPANA
A través de una herramienta que modela en tiempo real el comportamiento de los servicios industriales de la planta, Refinería Campana incorporó una nueva capacidad para optimizar consumos, identificar desbalances y mejorar su desempeño energético.
Por Fernando Díaz Falu, Javier Saavedra, Federico Bollati, Florencia Zapata Soto (Pan American Energy), Nicolás Carrara, Andrea Herrera, Sergio Yapur (KBC Advanced Technologies)
Este trabajo fue seleccionado del 7º Congreso Latinoamericano y del Caribe de Refinación del IAPG.
1. Introducción
Las industrias de refinamiento y petroquímicas operan con sistemas de energía complejos basados en redes de vapor de distintos niveles de presión, así como calderas de producción de vapor de alta presión que emplean distintos tipos de combustibles, y unidades de recuperación de calor que optimizan el uso energético a través del aprovechamiento de gases residuales. La integración eficiente de estos sistemas es fundamental para garantizar un suministro energético confiable, minimizar las pérdidas y reducir las emisiones. Por ello, la implementación de estrategias de control avanzado y modelos de optimización energética se ha convertido en una prioridad para mejorar la sostenibilidad y competitividad del sector.
La búsqueda de la eficiencia energética y la reducción de emisiones se ha convertido en una prioridad en todo el mundo, impulsada tanto por motivos económicos como ecológicos. En Argentina, la refinería de PAE en Campana, Buenos Aires, está liderando el camino hacia una operación más eficiente y sustentable. Pero este objetivo no está libre de desafíos y obstáculos, que incluyen precios variables, mercados en transición y un contexto internacional muy dinámico.
La refinería de PAE en Campana fue inaugurada en 1906 y se constituye como la más antigua de Sudamérica. Actualmente, y luego de varios proyectos de expansión y modernización, constituye un sitio de conversión total que satisface estándares internacionales y presenta una capacidad instalada de más de 95 mil barriles de crudo por día. La adopción de un Sistema de Gestión Energética (EMS por su sigla en inglés) ha sido un proyecto de importancia para mejorar la competitividad del sitio en base a la operación óptima del mismo.
Una exitosa gestión de la energía es una tarea compleja que debe hacer frente a una diversidad de condiciones operativas, variaciones de precios con los consecuentes cambios de carga en las plantas, unidades que entran o salen de servicio, errores característicos de instrumentación de campo, entre otras. En este entorno, mantener los balances de masa y energía del sitio actualizados y producir recomendaciones operativas efectivas es un desafío que solo puede llevarse a cabo con un algoritmo de optimización no lineal adecuado para la magnitud del problema, así como suficiente potencia computacional para ejecutarlo en un corto período de tiempo a intervalos regulares y en forma ininterrumpida.
Este artículo presenta la iniciativa de PAE en su refinería de Campana para optimizar el uso de energía y reducir emisiones a partir de la implementación de Visual MESA, un software que ofrece un Sistema de Optimización de Energía en Tiempo Real (ERTO por sus siglas en inglés), una herramienta avanzada enfocada a todo el sistema de servicios auxiliares.
Es aquí donde entra el concepto de gemelo digital, un modelo que se alimenta de datos actuales y reproduce el comportamiento del sitio, para responder a los desafíos anteriores. Los datos en tiempo real del sitio permiten estimar la situación presente en términos de balances de masa y energía, así como explorar movimientos operativos que mejoren el desempeño general del sitio. El incentivo para llevar a cabo las recomendaciones del sistema se expresa en términos del ahorro económico que las mismas producen. Estos ahorros pueden rondar fácilmente valores de millones de dólares anuales, y no involucran ninguna inversión alguna ya que se trata de aprovechar mejor los recursos existentes. Además, a lo largo de este artículo se estudian los detalles de esta implementación, así como el funcionamiento del sistema ERTO y su impacto en la refinería, destacando beneficios, desafíos y prospectiva a futuro.
Cabe destacar que, dada la naturaleza no lineal de los sistemas energéticos, que involucran variables de decisión tanto continuas como discretas; se utiliza una técnica de optimización no lineal mixta basada en programación cuadrática sucesiva (SQP, por sus siglas en inglés).
Las variables de optimización se agrupan en distintos niveles, de acuerdo con su impacto y capacidad de manipulación operativa, como se presenta en la siguiente tabla:
La definición de estos niveles permite que el sistema de optimización se adapte a distintos alcances, según las variables disponibles y su clasificación SQP.
2. Sistema de Gestión Integral de Energía
Para abordar estos desafíos, se ha implementado la herramienta VM-ERTO, que actúa como gemelo digital del sistema de servicios industriales de la refinería, permitiendo modelar las condiciones operativas en tiempo real y generar recomendaciones automáticas para reducir el costo energético sin afectar la operación de los procesos.
En PAE, el gemelo digital trabaja a lazo abierto y la función objetivo es el Costo Operativo, de manera de asegurar siempre una operación económica. Además, en la práctica suele comprobarse que una operación más eficiente conlleva a una reducción de emisiones.
Por otro lado, cabe destacar que también sería posible la implementación del gemelo digital a lazo cerrado.
La herramienta VM-ERTO es la única interfaz que permite a los usuarios acceder a información centralizada sobre las redes de servicios auxiliares como vapor, agua, combustibles y energía eléctrica.
Además de ofrecer recomendaciones para alcanzar una operación óptima y constituir una fuente centralizada de datos de los servicios auxiliares, el sistema VM-ERTO presenta otras características de interés a nivel de operaciones, ingeniería y gerenciamiento:
i. A través de su interfaz gráfica permite visualizar los balances de vapor, electricidad, agua, combustibles e hidrógeno. Dicha interfaz es accesible desde cualquier computadora que tenga privilegios adecuados y acceso a la intranet de PAE. Esto significa que solamente personal idóneo puede consultar el sistema.
ii. Conecta con las fuentes de datos disponibles en el complejo industrial, pudiendo traer miles de señales en forma simultánea. En la mayoría de los casos, estas señales provienen de la instrumentación de campo. Los datos de cada sensor son validados según el tipo de variable y la función que cumplen. Por ejemplo, se esperan temperaturas y presiones de sobrecalentamiento en la salida de una caldera de vapor. En el supuesto de que un sensor falle, Visual MESA es capaz de adoptar un valor conservativo para permitir estimar los balances de masa y energía en forma realista, evitando que ésta o cualquier otra falla perturbe las estimaciones en forma significativa.
iii. Además de la validación de datos, es posible llevar a cabo el filtrado de aquellas señales que presenten una relación señal-ruido importante. Es decir, se puede post procesar una señal ruidosa para mejorar la lectura de campo sin tener que intervenir la instrumentación de campo.
iv. La ejecución del código consta de dos fases, una llamada calibración (o simulación) y las fases de optimización, que se discutirán más adelante. En la fase de calibración, se obtienen los balances de masa y energía de los sistemas auxiliares de todas las plantas incluidas en el modelo. Esta generación automática e instantánea de los balances constituye una fuente de información de ingeniería muy útil, ya que aporta, por ejemplo, estimaciones de caudales y entalpías en cañerías sin instrumentación asociada.
v. En particular, los balances automáticos permiten detectar sensores que están funcionando en falla o que necesitan una recalibración. Los llamados “globos” del modelo, son elementos que dan una idea del error del balance en cada cabezal de vapor, línea de agua, o subred de tensión eléctrica. PAE ha usado activamente Visual MESA con el fin de mejorar el desempeño de la instrumentación de campo.
vi. La fase de optimización que implementa PAE a través del ERTO es de tipo “global”, esto es, incluye a todo el sitio y las restricciones operativas son lo suficientemente amplias para poder capturar los mayores beneficios posibles. Por otro lado, la optimización incluye tanto variables continuas como discretas. Es decir, algunas de las recomendaciones pueden sugerir, por ejemplo, reducir la apertura de una válvula de laminación en 20% (una variación continua) mientras que otras recomendaciones pueden ser intercambiar una bomba operada por motor eléctrico por su redundancia operada con turbina de vapor (una variación discreta, ya que involucra encendido y apagado de equipos).
vii. Tanto los resultados de las calibraciones (balances) como de la optimización (recomendaciones operativas) pueden extraerse en reportes de distintos tipos. Los mismos pueden también ser configurados para enviarse por correo internamente al grupo de gestión de energía.
viii. Además de los reportes periódicos que puedan generarse, un conjunto de resultados selectos se historizan para ser consultados a demanda en la base de datos del sitio. Entre los mismos se encuentra el registro de ahorros potenciales que pueden capturarse si se implementan las recomendaciones, así como la evolución de costos operativos en el tiempo.
3. Caso de Estudio: Modelo tipo Gemelo Digital del sistema de servicios auxiliares de PAE Campana
La solución de optimización implementada en la Refinería Campana de PAE ofrece tres funcionalidades clave:
i. Optimización energética en tiempo real
ii. Casos de estudio
iii. Monitoreo y auditoría centralizada del sistema de servicios industriales.
Gracias a esta tecnología, la refinería ha logrado identificar ahorros significativos, mejorar la eficiencia operativa y reducir los costos energéticos, todo en un entorno complejo con múltiples restricciones operativas y criterios de seguridad.
En la práctica, el modelo de Campana ha sido configurado para operar normalmente a nivel SQP 3, permitiendo la evaluación de intercambios entre turbinas de vapor y motores eléctricos, optimizando así el uso de energía mecánica y eléctrica.
La función objetivo minimiza el costo total de energía del sitio, expresado en ARS/h, mediante la siguiente expresión:
Costo Total Optimizable = Combustible + Electricidad + Otros Costos
Donde:
Combustible: incluye el costo del gas natural y otros combustibles internos (Diluyente y GLP).
Electricidad: refiere al precio de la energía eléctrica importada de red.
Otros Costos: contempla, por ejemplo, el costo del agua desmineralizada o del vapor importado en caso de aplicación.
La herramienta utiliza bloques de optimización para modificar variables manipulables, como el consumo de gas natural, y bloques de restricciones que establecen límites operativos, como caudales máximos o límites de composición en mezclas de combustibles. Esto permite encontrar un equilibrio óptimo entre disponibilidad, seguridad operativa y eficiencia económica, ajustado a las condiciones reales de la refinería.
Con estas capacidades, Refinería Campana puede tomar decisiones informadas en tiempo real, priorizando tanto la eficiencia operativa como el cumplimiento de sus compromisos ambientales y de sostenibilidad, apoyándose en una solución flexible y escalable. Es importante mencionar, que las soluciones de optimización deben ser validadas por el personal de planta, para garantizar que sean realizables y respeten las condiciones de seguridad.
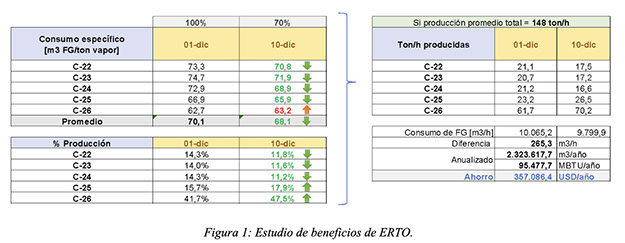
3.1 Estudio de beneficios por optimización en tiempo real
Visual MESA calcula en cada ejecución la eficiencia en tiempo real de las calderas y optimiza las cargas en base a dichos valores y sus curvas de eficiencia. PAE observó recomendaciones consistentes en cuanto a favorecer la producción de vapor en algunas calderas, y reducirlo en otras.
Como parte de las acciones concretas de optimización, se indicó a los operadores que ajustaran el parámetro de control denominado “disponibilidad” en las calderas. Este parámetro está relacionado con la capacidad de respuesta de cada caldera ante una disminución de la presión de vapor en el cabezal de alta, ya que la demanda se distribuye entre ellas en función del valor de disponibilidad asignado. A mayor disponibilidad, mayor es la sensibilidad de la caldera frente a los cambios en la demanda de vapor.
Inicialmente, todas las calderas tenían su disponibilidad configurada al 100%. Sin embargo, se implementó el siguiente cambio: se mantuvo la disponibilidad en 100% para las calderas más eficientes, mientras que se redujo al 70% para aquellas menos eficientes.
Como resultado, se observó una disminución en la generación promedio de las calderas menos eficientes y un aumento en la producción de las más eficientes. En términos de consumo de combustible (gas natural + fuel gas), el consumo promedio se redujo de 10.065,18 m³/h a 9.799,93 m³/h, lo que representa un ahorro de 265,25 m³/h, atribuible principalmente a la mejora en la eficiencia global del sistema de calderas. Si se anualiza este ahorro, se estima un beneficio económico del orden de 357.000 USD/año.
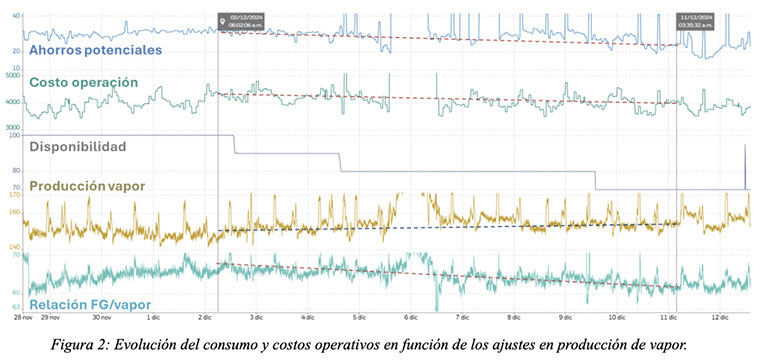
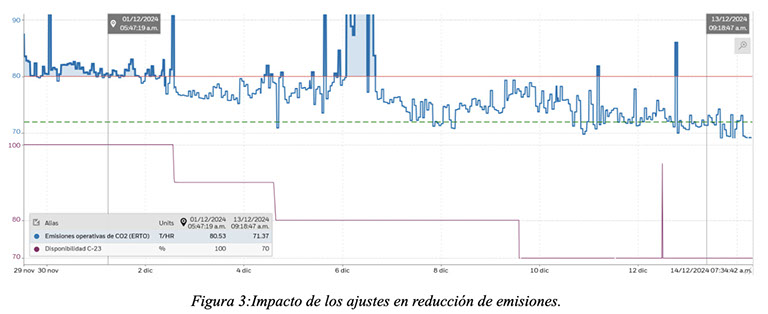
La figura adjunta muestra también la tendencia de la producción de vapor en relación con el consumo total de fuel gas. Se evidencia el mismo comportamiento: para una producción total de vapor de alta presión similar, el consumo total de combustible se redujo en promedio un 2,6%. A su vez, como consecuencia de una mejora en la eficiencia de la operación del sistema, se redujeron las emisiones de GEI conforme se fue avanzando con el ajuste de disponibilidades, lo que demuestra que una operación más eficiente hace a una operación más limpia también.
La optimización llevada a cabo no solo contempló las calderas, sino también numerosas variables de optimización como cargas en turbogeneradores, importación de electricidad y de vapor, reducción de venteos de vapor, caudal de fuel gas a antorchas, cambios turbina/motor, laminaciones, entre otros. Los operadores, reciben los reportes con la información para aplicar los cambios y acciones concretas de optimización, que se analizan regularmente al inicio de cada turno. La optimización del sitio completo es una de las grandes ventajas de tener un único modelo de los servicios auxiliares, dado a que se puede calcular de este modo el impacto de cada acción sobre todo el sistema.
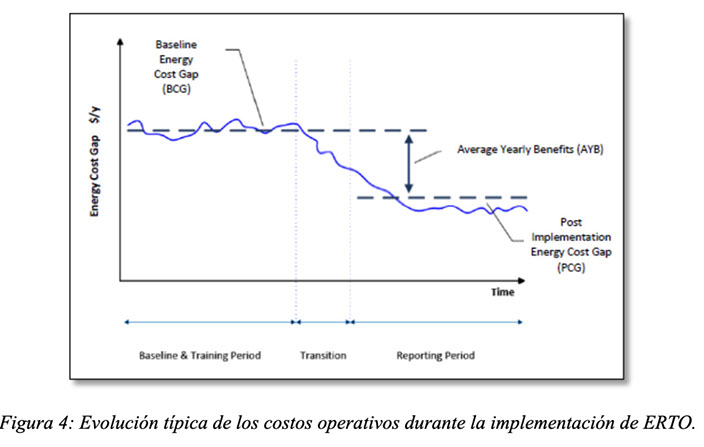
Para estimar los beneficios totales capturados por la optimización en tiempo real, se lleva a cabo un método en el cual se ejecuta la optimización sin aplicar las recomendaciones en campo. Este periodo se ejecuta durante un tiempo suficiente para generar una línea base de beneficios potenciales (BCG). A partir de un momento dado, las recomendaciones comienzan a aplicarse y se observa que los beneficios potenciales se reducen significativamente, para alcanzar un nivel inferior (PCG). La diferencia entre BCG y PCG puede calcularse como el beneficio capturado, y si el sitio se mantiene operando en los niveles de PCG este beneficio puede anualizarse, para estimar un beneficio anual (AYB), por ejemplo.
Es importante destacar que algunas mejores prácticas operativas fueron identificadas en las primeras etapas del proyecto y comenzaron a ser implementadas antes de realizar el cálculo de los beneficios, de manera que PAE consiguió capturar beneficios antes de la aplicación del método de estimación mencionado.
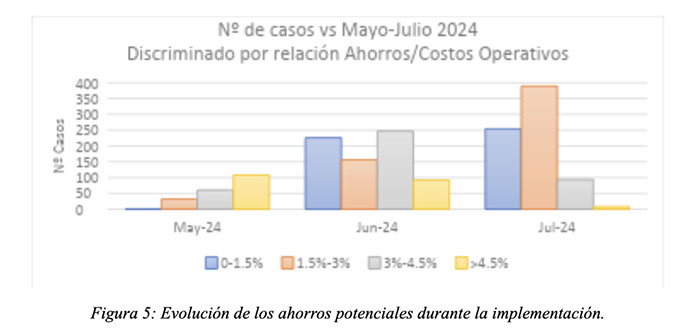
Para el cálculo de los beneficios capturados, se ejecutó una línea base en el mes de mayo 2024. Durante el mes de junio 2024, algunas recomendaciones comenzaron a ser aplicadas, y a partir julio de 2024 las recomendaciones comenzaron a aplicarse de manera más sistemática.
Los beneficios capturables y anualizados fueron estimados en 1,016 MMUSD/año, mientras que la reducción de CO2 fue estimada en 9,636 MTon CO2/año.
3.2 Casos de estudio e impacto operativo
El gemelo digital puede ser usado para predecir el comportamiento del sistema de servicios auxiliares ante uno o más cambios operativos. Estos casos, en principio hipotéticos, pueden realizarse sobre la base de datos actuales, promedios recientes para cada variable de entrada, o eventualmente datos históricos. En consecuencia, estos cambios operativos pueden analizarse en forma aislada o en conjunto, bajo condiciones actuales, pasadas, o incluso futuras de operación, si se conoce la entrada de datos adecuada.
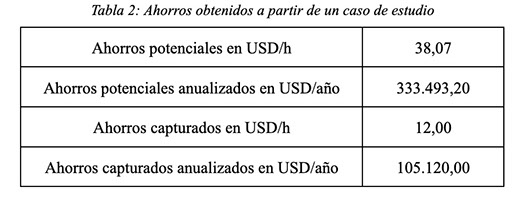
Un caso de estudio concreto que fue implementado en la práctica a partir de la herramienta constituye la modificación de la admisión del turbogenerador de vapor 5 (STG-5) con el encendido de la turbina de vapor BP-12. Esta combinación particular de cambios permitió capturar 12 USD/h de costos operativos. Esto representa el 31% de los ahorros potenciales que sugiere el caso de estudio. Estos resultados se resumen en la siguiente tabla.
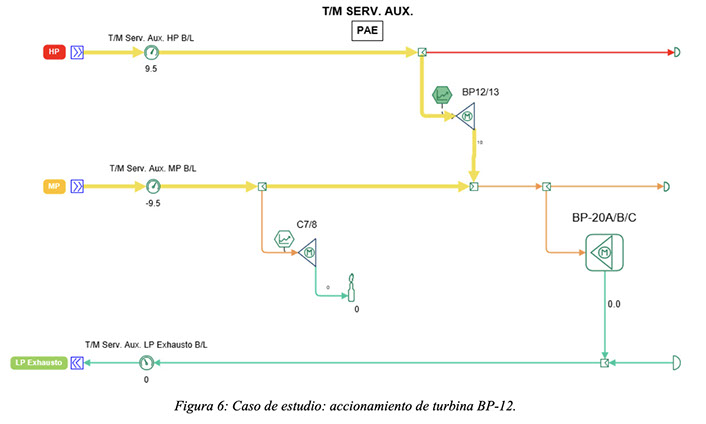
La Figura 1 presenta un diagrama generado por la herramienta luego de la optimización. En el mismo se destaca con línea amarilla el encendido de la turbina BP-12 y el correspondiente incremento de caudal de vapor hacia la misma. Este tipo de diagrama permite una interpretación de resultados rápida, por simple inspección.
Cabe notar que esta maniobra no modifica el balance de vapor de la planta, y en consecuencia no altera los valores de consigna de las calderas. Esto ocurre debido a que el caudal de vapor que deja de consumir el turbogenerador STG-5 se redirige a la turbina BP-12. El impacto en el costo operativo se debe a la eficiencia relativa entre estos dos equipos y al precio de la potencia eléctrica. En otras palabras, resulta más económico usar vapor en lugar de electricidad para accionar una bomba de proceso, que usar ese vapor para generar un adicional de potencia eléctrica in situ a través del turbogenerador STG-5.
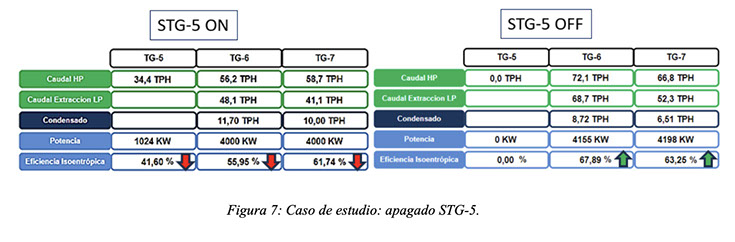
A su vez, no sólo se estudió la posibilidad de reemplazo de parte de la producción del STG-5 con la turbina en cuestión, sino también el apagado de este turbogenerador. Permitiéndole al modelo contemplar caudales de admisión iguales a 0, se encontró que resulta más eficiente para el sistema quitar de servicio este equipo y mantener operativos sólo los otros dos turbogeneradores existentes. Así, se consiguió:
- Disminución del consumo de vapor en aproximadamente 7 ton/h (refleja la ineficiencia del equipo).
- Aumento en la eficiencia general del sistema de generación eléctrica (mejores puntos de operación para los dos turbogeneradores restantes).
- Ahorro potencial anualizado de aproximadamente 193.000 USD/año (22 USD/h).
Al día de la fecha, se mantiene el equipo fuera de servicio y funciona únicamente como spare de los otros turbogeneradores.
Si bien la herramienta constantemente propone cambios adicionales que permitirían capturar mayores ahorros potenciales, este caso revela como determinados cambios operativos relativamente sencillos pueden mejorar el costo operativo en forma apreciable.
3.3 Información centralizada, monitoreo y auditoría
La información se integra desde el historiador de planta a través de conectores OPC, mientras que ciertas variables —como precios de energía, límites de operación o estados de equipos— pueden ser actualizadas manualmente. El sistema ejecuta rutinariamente, cada 1 hora, simulaciones de calibración para monitoreo y lleva a cabo una optimización, generando reportes estandarizados y paneles visuales que presentan de manera clara los resultados clave para la operación.
La herramienta permite también evaluar la brecha entre los costos reales de operación y los costos óptimos, lo cual proporciona un insumo clave para auditorías internas y mejora continua. El sistema alerta automáticamente a los responsables del área energética cuando detecta oportunidades significativas de mejora, lo que facilita la priorización de acciones correctivas.
Además, el sistema calcula los costos marginales asociados a vapor, electricidad y combustibles, información que resulta esencial para comparar la generación interna frente a opciones externas y para evaluar el desempeño energético de cada unidad de proceso.
Entre los indicadores de desempeño energético calculados e historizados por el sistema se incluyen:
i. Eficiencias térmicas de calderas
ii. Eficiencia de hornos de proceso
iii. Desbalances en los diferentes niveles de presión de vapor
iv. Costos actuales y optimizados de energía, así como emisiones de CO₂
v. Costos marginales de los distintos vectores energéticos (vapor de diferentes niveles, electricidad, agua de calderas y combustibles)
Los desbalances detectados en las redes de servicios industriales suelen estar asociados a errores de medición o a consumos sin instrumentación suficiente. El modelo los cuantifica y los mantiene constantes en el proceso de optimización, de modo que las recomendaciones se ajustan a la demanda energética real del sistema. Esto permite a la Refinería Campana identificar con mayor precisión los focos de ineficiencia y definir acciones concretas para su corrección.
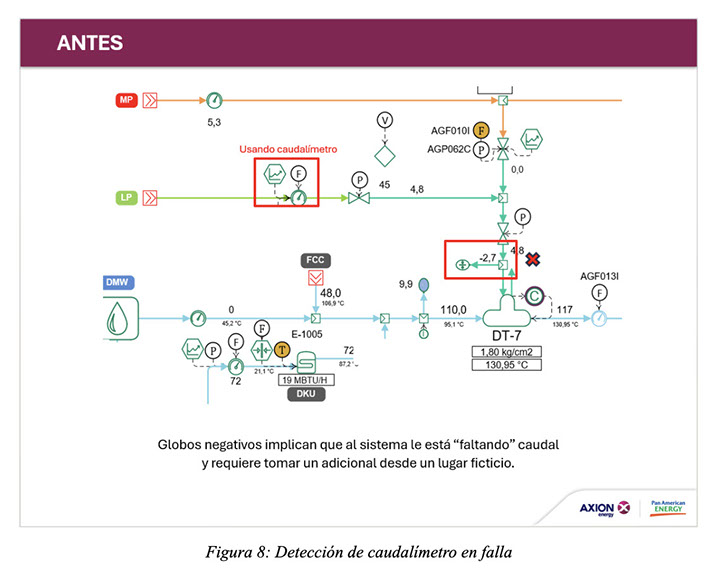
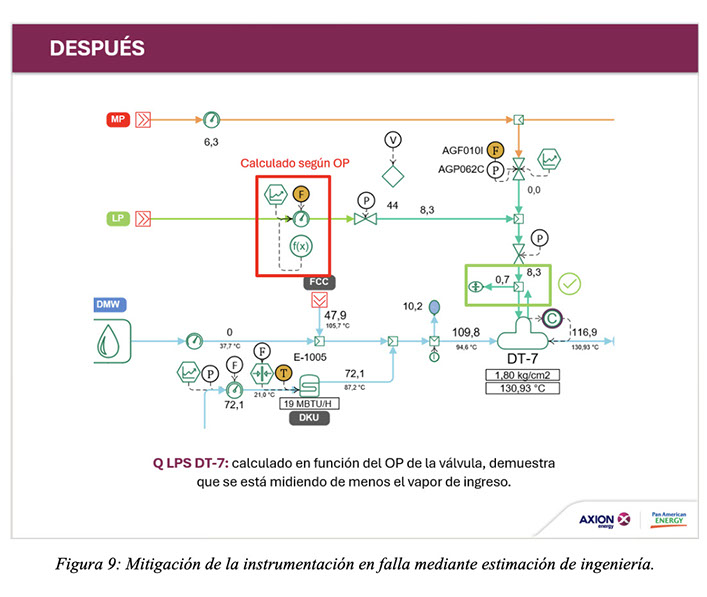
Sin embargo, la presencia de desbalances en las redes de servicios auxiliares es analizado por el área de energía con el fin de determinar sus causas y, en lo posible, poder minimizarlos. En la siguiente figura se muestra un ejemplo concreto donde se observa en la situación inicial un desbalance en el cabezal de vapor de baja (LP), entre el valor medido y el valor de consumo teórico calculado por el desaireador, cuyo valor era de 2,7 TPH. Mediante el análisis de los sensores involucrados, se identificó que el sensor de caudal utilizado era el causante de una medición errónea, y se reemplazó este sensor en el modelo por el sensor de apertura de la válvula de esa línea (escalado de porcentaje de apertura a caudal mediante la curva de la válvula), obteniendo una mejora significativa en la resolución del balance de masa de LP. El desbalance en esta nueva situación bajó a 0,7 TPH. Similares iniciativas de monitoreo de instrumentos de medición se llevaron a cabo en diferentes áreas de la refinería, donde se encontraron situaciones similares. Como resultado de este análisis, se enviaron a revisión y mantenimiento todos los sensores sospechosos.
3.4 Otras aplicaciones prácticas
Además de la captura de ahorros potenciales que habilita la optimización y de los casos desarrollados anteriormente, se pueden listar otros beneficios derivados de la herramienta VM-ERTO, como ser:
1. Se realizó un caso de estudio para evaluar una oferta del gobierno para aliviar la carga en la demanda eléctrica durante el verano de 2025. La oferta consistía en un incentivo para reducir el consumo eléctrico. El caso de estudio involucraba estudiar la relación entre el consumo eléctrico total y el impacto de su variación en el costo.
2. Relevamiento directo de datos desde la interfaz del modelo, a partir de información de sensores y cálculos de gases de combustión, incluyendo eficiencia, porcentaje de oxígeno en chimenea, temperatura de chimenea y consumo de combustible. Todo esto permitió mejorar el monitoreo de hornos y quemadores.
3. Detección de sensores poco confiables y reconfiguración del desaireador DT-5.
4. Incorporación de disponibilidad de calderas para seguimiento y eventual balanceo de carga.
5. Actualización de las curvas de eficiencia de los turbogeneradores.
6. Estimación del costo de generación eléctrica con los turbogeneradores.
7. Estimación de varios caudales a partir de tags de apertura de válvulas.
Estas tareas concretas han permitido una mejora continua en los sistemas de servicios auxiliares.
4. Conclusiones
En el contexto actual de transición energética y mayor exigencia en materia ambiental y económica, la Refinería Campana de PAE ha avanzado decididamente en la incorporación de tecnologías digitales para optimizar su desempeño energético y operativo. Uno de los pilares de esta transformación ha sido la implementación del sistema VM-ERTO, una herramienta que permite modelar en tiempo real la red de servicios industriales y proponer acciones concretas para reducir costos energéticos y mejorar la eficiencia del sistema.
A través de esta solución, la refinería ha logrado identificar oportunidades de mejora continua, implementar medidas correctivas de manera ágil y avanzar hacia una operación más eficiente y sustentable. Los beneficios obtenidos se reflejan no solo en el plano económico, mediante el ahorro de recursos, sino también en el uso más racional de la energía y la reducción del impacto ambiental asociado.
La experiencia en Campana también demuestra que la tecnología, por sí sola, no alcanza. La integración efectiva del sistema ha requerido un trabajo coordinado entre distintas áreas de la refinería, así como el compromiso de los equipos operativos, que han recibido capacitaciones y acompañamiento técnico para incorporar el uso de la herramienta como parte de la rutina diaria. Esta cultura de mejora continua ha sido clave para maximizar los resultados y sostenerlos en el tiempo.
Asimismo, la posibilidad de centralizar la información energética, monitorear indicadores clave (como eficiencias, costos marginales, consumos y emisiones) y contar con reportes automáticos y trazables, ha fortalecido los procesos de auditoría interna y toma de decisiones basadas en datos.
De cara al futuro, la Refinería Campana continúa avanzando en su estrategia de eficiencia energética, confiando en el valor que aporta la digitalización para adaptarse a las nuevas demandas del sector. En un entorno en el que se exige mayor competitividad, menores emisiones y productos de mayor valor, tecnologías como VM-ERTO se consolidan como aliadas fundamentales para una operación segura, eficiente y sustentable.
5. Bibliografía
● Real Time Digital Twin Based Energy Optimization at Ecopetrol Barrancabermeja – Efficient and Profitable Decarbonization, César Augusto Batista (Ecopetrol) and Cristian Germán Rojas (KBC), Latin American Refining Technology Conference (LARTC), Rio de Janeiro, Brazil, September 2023
● Energy Cost Reduction at a German Petrochemical Complex, Energy Department INEOS Köln GmbH, Soteica Visual MESA, ERTC Energy Efficiency, Lisbon, Portugal, November 2016.
● Reducing Energy Costs While Improving Efficiency, J.P. Ruiz, A. Bolíbar, D. Ruiz, D. Alonso, G. Morrón, Hydrocarbon Processing, 57-60, June 2015.
● Reducción de Costes Energéticos en Un Complejo Químico con un Modelo en Línea, Departamento de Optimización y Control, CEPSA Palos de la Frontera, Marcos Kihn and Diego Ruiz, Industria Química, Spain, 48-55, April 2015.
● Online Monitoring and Optimization of the Energy System at Motiva Port Arthur Refinery, Robert Aegerter, Jake Lam, Raul Adarme (Motiva), Jorge Mamprin, Carlos Ruiz, Pablo Montagna (KBC), Industrial Energy Technology Conference (IETC), New Orleans, June 2018.
● Industrial Energy Management with Visual MESA at BP Lingen refinery, Availability Department - BP Lingen refinery, Soteica. European Refining Technology Conference (ERTC) Annual Meeting, Vienna, Austria, November 2012.
● Finding Benefits by Modeling and Optimizing Steam and Power Systems, M. Reid, C. Harper, C. Hayes, Industrial Energy Technology Conference (IETC), New Orleans, May 2008.
● Site Wide Energy Cost Reduction at TOTAL Feyzin Refinery, Departament Procédés - Energie, Logistique, Utilités (TOTAL Raffinerie de Feyzin - France), Jorge Mamprin, Diego Ruiz, Carlos A. Ruiz, European Refining Technology Conference (ERTC) 12th Annual Meeting, Barcelona, Spain, November 2007.
● Centro de Información Técnica Refinería Campana (CIT).





> SUMARIO DE NOTAS
TRANSICIÓN ENERGÉTICA. PRODUCCIÓN DE E-FUELS PARA LOS SECTORES DE AVIACIÓN Y MARÍTIMO
MODELIZACIÓN DE EMISIONES DE GHG EN LA PLANIFICACIÓN DE LA REFINERÍA
UN ENFOQUE PASO A PASO PARA REDUCIR LA HUELLA DE CO₂ A TRAVÉS DE UNIDADES SRU
IMPLEMENTACIÓN DE TECNOLOGÍA DE GEMELO DIGITAL COMO SISTEMA DE MANEJO DE LA ENERGÍA EN REFINERÍA CAMPANA
> Ver todas las notas


Instituto Argentino del Petróleo y del Gas
Maipú 639 (C1006ACG) - Tel: (54 11) 5277 IAPG (4274)
Buenos Aires - Argentina
> SECCIONES
> NUESTRAS REDES
Copyright © 2025, Instituto Argentino del Petróleo y del Gas,todos los derechos reservados