


NOTA DE TAPA
EFICIENCIA ENERGÉTICA EN LA REMOCIÓN DE GASES ÁCIDOS MEDIANTE SOLVENTES FORMULADOS
A partir de simulaciones, pruebas piloto y una conversión en línea en refinería, el estudio demuestra que los solventes formulados con aminas pueden reducir el consumo de energía y mejorar la recuperación de hidrocarburos en procesos de remoción de gases ácidos.
Por Diego E. Cristancho, Jason Binz, Bala Sreedhar, Michelle Valenzuela y Andrés F. Porras Giraldo, (Dow)
Este trabajo fue seleccionado del 7º Congreso Latinoamericano y del Caribe de Refinación del IAPG.
Los procesos de endulzamiento (gas treating) se han utilizado durante décadas en refinerías y plantas de gas para remover H2S, CO2, mercaptanos (RSH) y otros contaminantes de las corrientes. Los procesos de endulzamiento de gas son requeridos para cumplir especificaciones ambientales estrictas [1], minimizar emisiones de gases ácidos y reducir su impacto en operaciones aguas abajo.
Para el caso de tratamiento de corrientes de gas licuado de petróleo (LPG) los contaminantes sulfuro de carbonilo (COS) y RSH representan grandes desafíos en la remoción. Existen diversas alternativas para el tratamiento de LPG ácido, cuya selección depende de varios factores: tipo y concentración de contaminantes en las corrientes, especificaciones del producto final, integración con las operaciones de refinería, costos de inversión y operación (CAPEX y OPEX). así como la confiabilidad o integridad del sistema, la corrosión y la degradación de materiales.
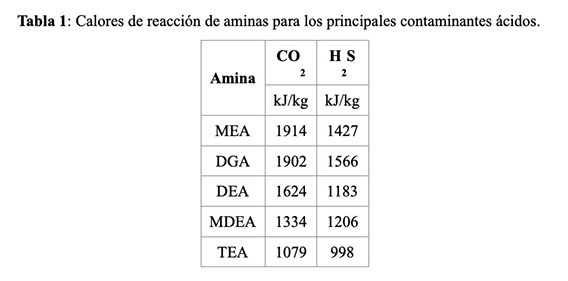
Tradicionalmente estos procesos de remoción emplean soluciones de aminas (compuestos orgánicos derivados del amoníaco) y, si bien son efectivos para la captura de gases ácidos, su regeneración implica altos costos energéticos y operativos. Se estima que alrededor del 70% de los costos operativos (excluyendo mano de obra) de una unidad de endulzamiento con aminas provienen de la energía requerida en la regeneración del solvente [2]. Esto implica que cualquier mejora en la eficiencia de esta etapa se traduciría en un impacto significativo en la economía y sostenibilidad de las refinerías.
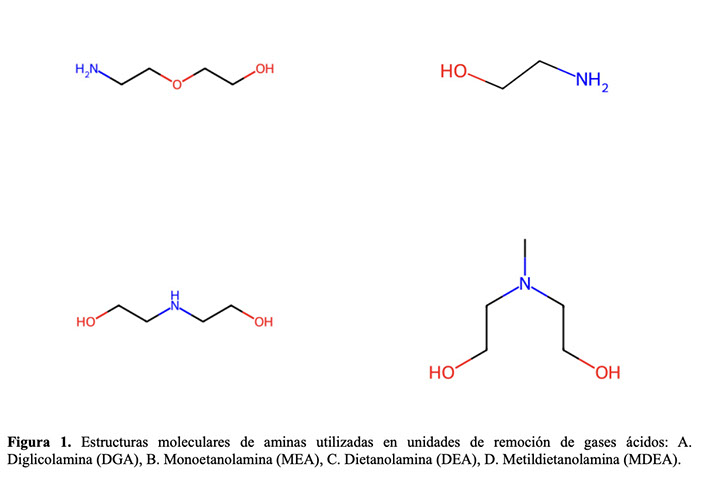
Las aminas más utilizadas en la industria incluyen Monoetanolamina (MEA), Dietanolamina (DEA), Metil-Dieatanolamina (MDEA), Diglicolamina, entre otras (Ver Figura 1). Cada una con sus ventajas y desventajas según el proceso y condiciones operativas [3]. Adicionalmente, existen las denominadas aminas formuladas que son mezclas de dos o más aminas que son implementadas para sobrepasar las limitaciones de propiedades físicas y químicas que presentan las aminas puras [4].
En este contexto, el presente trabajo explora un enfoque innovador para la evaluación de alternativas para la remoción de contaminantes, combinando simulaciones de una unidad integrada de remoción y pruebas de remoción a escala piloto en las corrientes. El producto de este trabajo propone el uso de aminas formuladas para reducir el consumo de energía en el ciclo de regeneración y minimizar las pérdidas de hidrocarburos asociadas al proceso, en comparación con los solventes tradicionales.
Desarrollo
El esquema básico de una unidad típica de aminas consiste en un contactor donde el gas agrio (con contaminantes) entra en contacto con una solución acuosa de amina, que absorbe los gases ácidos de la corriente, y un regenerador (stripper) donde la amina rica (con contaminantes en solución) se calienta para liberar el H2S/CO2 y recuperar las especificaciones de la amina pobre (regenerada), que se recircula al absorbedor, ver Figura 2. El gas tratado (gas dulce) sale del absorbedor con un contenido de H2S muy bajo, cumpliendo con las especificaciones operativas.
Para este trabajo se ha elegido presentar una unidad de amina para el tratamiento de gases ácidos en una unidad de LPG en una refinería que usa Diglicolamina según la siguiente configuración:
Se recolectaron muestras de LPG agrio y tratado, y se asumió que los resultados de especiación de azufre obtenidos eran correctos. En algunos casos, las composiciones de gas ácido calculadas a partir de las muestras de amina rica y pobre no coincidieron con los resultados de las muestras de gas o LPG. No obstante, al utilizar directamente los valores medidos en las muestras de gas/LPG, en lugar de composiciones calculadas, el balance total de gas ácido obtenido mostró una alta concordancia con la tasa de gas ácido medida. En general, se observaron niveles de H₂S más bajos de lo esperado en las corrientes de salida, lo cual podría atribuirse a la absorción de H₂S en las bombas de muestreo si estas no estaban adecuadamente recubiertas o pasivadas.
Evaluación experimental a escala piloto
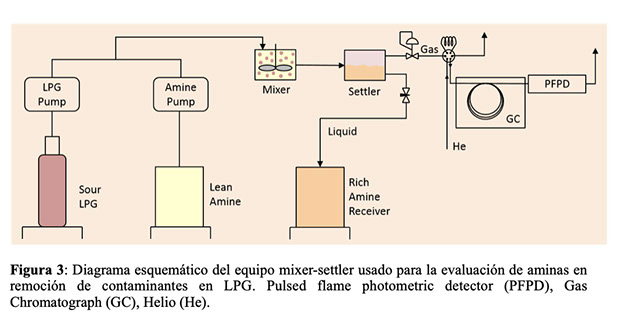
Con el propósito de evaluar la performance de cuatro diferentes aminas como solventes de contaminantes para una corriente de prueba de LPG, se instaló el montaje que se presenta esquemáticamente en la Figura 3. La prueba consiste en dos corrientes, una de LGP y otra de amina pobre que se ponen en contacto, se mezclan y se estudian las condiciones de separación en el settler y se miden las concentraciones de contaminantes después de la separación por medio de cromatografía gaseosa en la corriente tratada empleando un Detector Fotométrico de Llama Pulsada (PFPD). Este equipo permite evaluar la remoción de contaminantes en la corriente en amplios rangos de condiciones de temperatura y de presión, constituyendo una herramienta de gran valor a la hora de optimizar la selección de formulaciones de amina con base en su performance.
Simulaciones
Para complementar los hallazgos de las evaluaciones experimentales, se propuso simular el proceso en dos etapas, mediante el uso del software ProComp 10, esta herramienta de cómputo fue desarrollada internamente y permite obtener balances de materia y de energía muy cercanos a las condiciones operativas.
Etapa 1: Se simuló la unidad de amina (Figura 2) asumiendo una única etapa de equilibrio y utilizando las condiciones de composición de entrada, temperatura, presión y relación LPG/ amina de la operación.
Etapa 2: Se fijaron las condiciones el regenerador de forma que la corriente de entrada al regenerador es la de salida de amina rica (concentración y flujo) del primer experimento. Se busca reducir los niveles de ácidos y minimizar la corrosión en la línea de la amina pobre.
Resultados
Se realizaron corridas en el montaje experimental para las 4 diferentes aminas, una amina primaria la cual es la que actualmente están utilizando en la operación, una amina convencional altamente implementada en la remoción de H2S y dos aminas formuladas propuestas para una remoción controlada de los principales contaminantes detectados en el proceso.
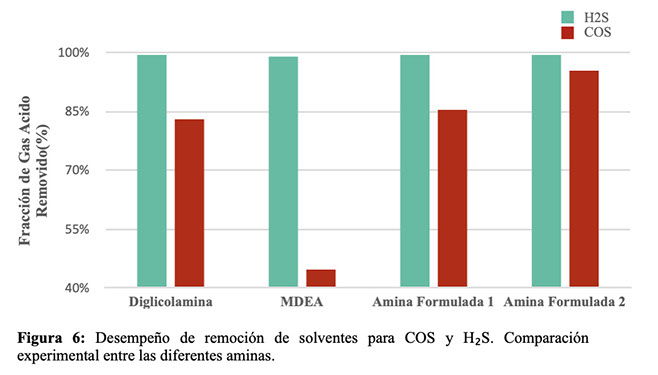
La Figura 6 presenta el porcentaje de remoción de H2S y de COS de la alimentación de LPG, la tabla con los valores puntuales y tiempo de residencia se presenta como anexo al final del documento. De estos resultados se puede observar que todas las aminas evaluadas presentan una importante capacidad de remoción en lo que respecta a H2S, sin embargo, en materia de remoción de COS, identificado como un contaminante difícil de remover, la MDEA presenta una pobre absorción, con la Amina Formulada 1 fue posible obtener una remoción ligeramente superior a la Diglicolamina, mientras que con la Amina Formulada 2 se obtuvo la mayor remoción de COS del experimento.
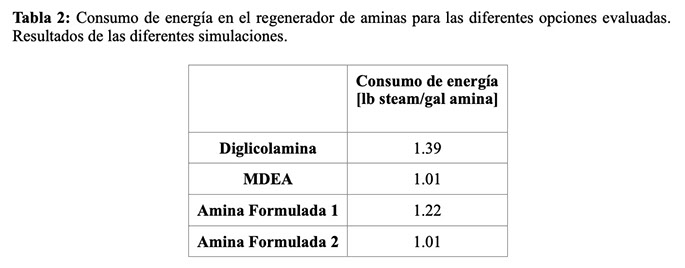
En la Tabla 2 se muestran los resultados de consumo de energía en el regenerador para las simulaciones con las diferentes aminas ricas. Con respecto a la Diglicolamina, el calor requerido para remover el H2S hasta alcanzar los valores de especificación es menor con las dos aminas formuladas, obteniéndose mejor resultados con Amina Formulada 2.
Tabla 2: Consumo de energía en el regenerador de aminas para las diferentes opciones evaluadas. Resultados de las diferentes simulaciones.
Comparando los resultados de la simulación y el experimento podemos rescatar que la mejor propuesta para la eliminación de contaminantes es la es la Amina Formulada 2 que alcanza valores altos de remoción de COS/H2S y presenta al mismo tiempo el menor consumo de energía en el proceso de regeneración, representando un ahorro calculado de 27% con respecto a la amina que utiliza actualmente en el proceso estudiado. Ahorros adicionales en el bombeo y circulación del sistema de amina fueron calculados, pero no son presentados al detalle este trabajo por pedido de la refinería.
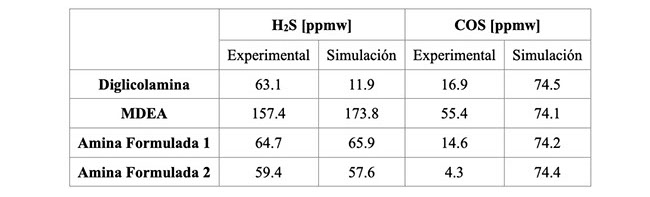
Tabla 3: Comparación de remoción de contaminantes en el contactor experimental y según simulaciones*.
Los resultados de la comparación entre las especificaciones medidas de H2S y COS en el LPG tratado difieren significativamente por el hecho de que este trabajo se ha realizado sin optimización de parámetros de la solución de amina debido a la falta de información inicial. Esto representa una oportunidad de mejora en la evaluación de proceso y evidencia la necesidad de verificaciones experimentales a la hora de evaluar solventes alternativos para unidades que actualmente se encuentran en operación por una marcada discrepancia observada en los resultados según la metodología (experimental vs analítica).
Conclusiones
● Se ha construido un aparato de laboratorio para evaluar solventes de aminas en aplicaciones de tratamiento de líquidos de LPG, y se ha demostrado que ofrece un desempeño de separación de H₂S y COS similar al logrado en unidades de tratamiento de líquidos a escala industrial.
● Las opciones de simulación existentes no predijeron con precisión la eliminación de COS en unidades de extracción de líquidos de LPG. Se requiere mejorar las herramientas actuales; la información experimental recopilada en este estudio puede utilizarse con ese propósito.
● Los resultados experimentales y de simulación muestran que las Aminas Formuladas 1 y 2 superaron a la MDEA y a la Diglicolamina, logrando mayores niveles de eliminación de H₂S y COS del LPG con menor consumo de energía necesario en la regeneración.
● Es muy importante destacar la relevancia de combinar la capacidad de simulación y la experimental para predecir correctamente el desempeño en la eliminación de componentes de azufre (H₂S y COS en este caso) de las corrientes de LPG.
Bibliografía
[1] Secretaría de Energía. (2023). Resolución 492/2023 - Combustibles: especificaciones. Ministerio de Economía, Argentina. Publicada en el Boletín Oficial el 9 de junio de 2023. Recuperado de https://www.argentina.gob.ar/normativa/nacional/resoluci%C3%B3n-492-2023-384937
[2] Erdmann, E., Ruiz, L. A., Martínez, J., Gutiérrez, J. P., & Tarifa, E. (2012). Endulzamiento de gas natural con aminas: simulación del proceso y análisis de sensibilidad paramétrico. Avances en Ciencias e Ingeniería, 3(4), 89–101. ISSN: 0718-8706.
[3] Nihmiya, A. R., & Ghasem, N. (2024). Application of amines for natural gas sweetening. En Advances in Natural Gas: Formation, Processing, and Applications (Vol. 2). Elsevier. https://doi.org/10.1016/B978-0-443-19217-3.00006-4
[4] Polasek, J. C., Iglesias-Silva, G. A., & Bullin, J. A. (1992). Using mixed amine solutions for gas sweetening. Proceedings of the Seventy-First GPA Annual Convention, 58–63. Gas Processors Association, Tulsa, OK.
Anexo
Los resultados de los experimentos de remoción de contaminantes están tabulados en la tabla A. Cabe señalar que estos experimentos comparan los resultados de separación obtenidos utilizando una sola etapa de contacto. Para cualquier solvente de amina, es probable que se logre una mayor remoción utilizando múltiples etapas de contacto.
Breve CV de los autores
Diego Cristancho
Research Scientist, Global Process Technology Leader EOA/EA, CHEN and Physics Universidad Industrial de Santander, Ms. CHEN
Texas A&M University, PhD CHEN
15 años en Dow. Experiencia en investigación científica aplicada a tecnologías de procesos globales, con enfoque en ingeniería química y física. Liderazgo técnico en iniciativas estratégicas de innovación.
Jason Binz
Research Scientist, Application Technology Leader
Penn State University, PhD in Chemical Engineering
University of Delaware, Bachelor’s in chemical engineering, Bachelor’s in Mechanical Engineering
12 años en Dow, anteriormente en Dow Energy (Oil & Gas). Experiencia en desarrollo de tecnologías aplicadas, con enfoque en soluciones energéticas y aplicaciones industriales.
Bala Sreedhar
Research Scientist
International Max Planck Research School, Magdeburg, Germany, PhD in Chemical Engineering
Georgia Tech, Atlanta, Postdoctoral Research
11 años en Dow investigando tecnologías de separación química para múltiples negocios de la compañía. Experiencia en investigación avanzada y desarrollo de soluciones innovadoras en procesos de separación.
Michell Valenzuela
Sales Director
Michigan State University, MBA
Texas A&M University, BSC
Rice University, Chemist
25 años en Dow, con experiencia en investigación de procesos, servicio técnico y desarrollo en Oil & Gas. Actualmente directora de ventas, liderando estrategias comerciales y relaciones con clientes clave.
Andrés Felipe Porras Giraldo
Líder Técnico
Universidad Nacional del Sur (UNS), Argentina, Doctor en Ingeniería Química.
Universidad Nacional de Colombia, Ingeniero en Petróleos
2 años en Dow, 13 años de experiencia en investigación y desarrollo, incluyendo modelado termodinámico y evaluación de proyectos. Enfoque en soluciones técnicas para procesos industriales complejos.




> SUMARIO DE NOTAS
TRANSICIÓN ENERGÉTICA. PRODUCCIÓN DE E-FUELS PARA LOS SECTORES DE AVIACIÓN Y MARÍTIMO
MODELIZACIÓN DE EMISIONES DE GHG EN LA PLANIFICACIÓN DE LA REFINERÍA
UN ENFOQUE PASO A PASO PARA REDUCIR LA HUELLA DE CO₂ A TRAVÉS DE UNIDADES SRU
IMPLEMENTACIÓN DE TECNOLOGÍA DE GEMELO DIGITAL COMO SISTEMA DE MANEJO DE LA ENERGÍA EN REFINERÍA CAMPANA
> Ver todas las notas


Instituto Argentino del Petróleo y del Gas
Maipú 639 (C1006ACG) - Tel: (54 11) 5277 IAPG (4274)
Buenos Aires - Argentina
> SECCIONES
> NUESTRAS REDES
Copyright © 2025, Instituto Argentino del Petróleo y del Gas,todos los derechos reservados